开源轻量级基于LLM的文档解析模型:MonkeyOCR,性能高速度快
MonkeyOCR 采用结构-识别-关系 (SRR) 三元组范式,它简化了模块化方法的多工具管道,同时避免了使用大型多模态模型进行整页文档处理的低效率。
GitHub:https://github.com/Yuliang-Liu/MonkeyOCR
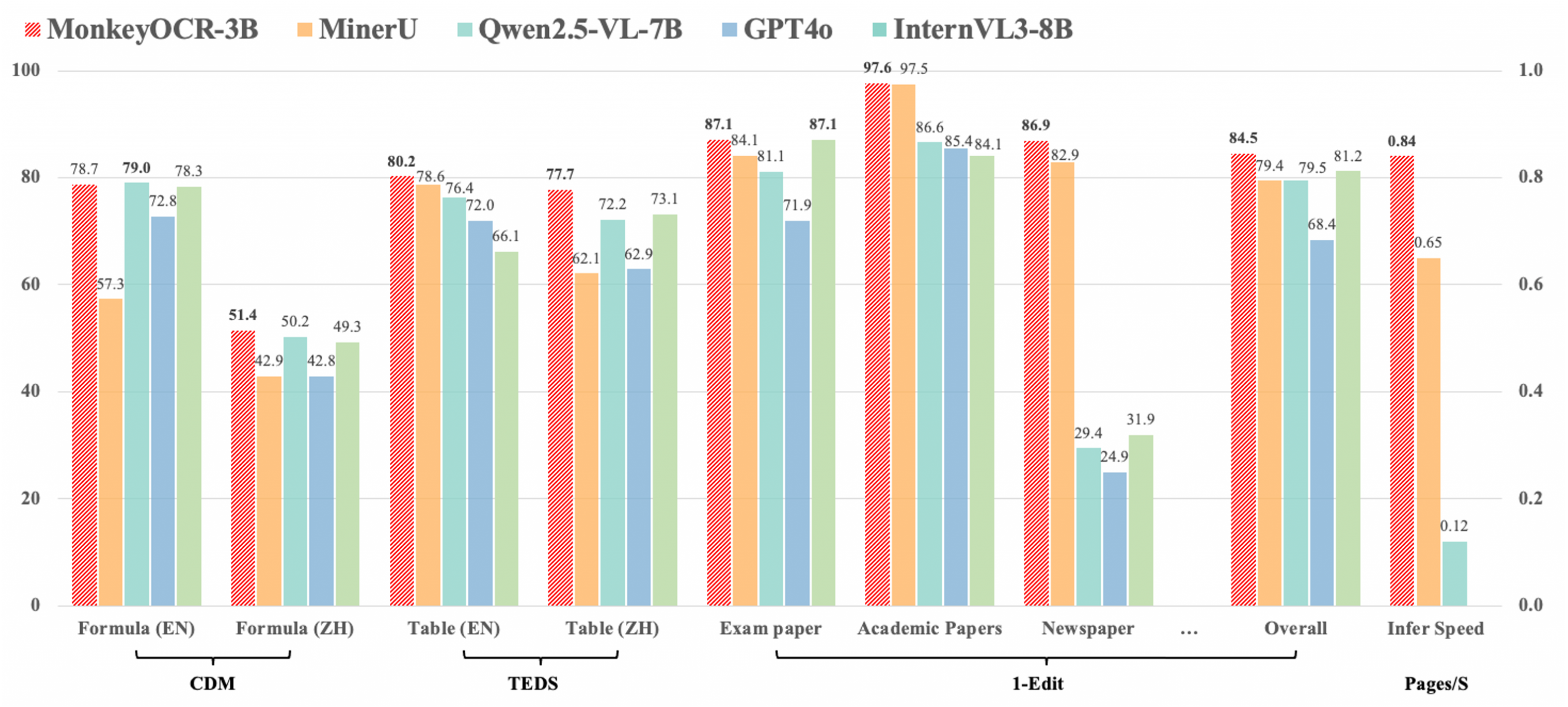
- 与基于管道的方法 MinerU 相比,我们的方法在 9 种中英文文档中实现了 5.1% 的平均改进,其中公式提高了 15.0%,表格提高了 8.6%。
- 与端到端模型相比,我们的 3B 参数模型在英文文档上实现了最佳的平均性能,优于 Gemini 2.5 Pro 和 Qwen2.5 VL-72B 等模型。
- 对于多页文档解析,我们的方法达到了每秒 0.84 页的处理速度,超过了 MinerU (0.65) 和 Qwen2.5 VL-7B (0.12)。
版权声明:本站所有文章版权均归AiNeuOS所有,任何个人、媒体、网站、团体等注明来源后均可以转载。但是不得在非我站的服务器上建立镜像,否则,我站将依法保留追究相关法律责任的权利。
关注公众号:
