开源docext利用视觉语言模型 (VLM) 从文档图像中准确识别和提取现场数据和表格信息
docext 是一种无 OCR 工具,用于从发票、护照和其他文档等文档中提取结构化信息。它利用视觉语言模型 (VLM) 从文档图像中准确识别和提取现场数据和表格信息。
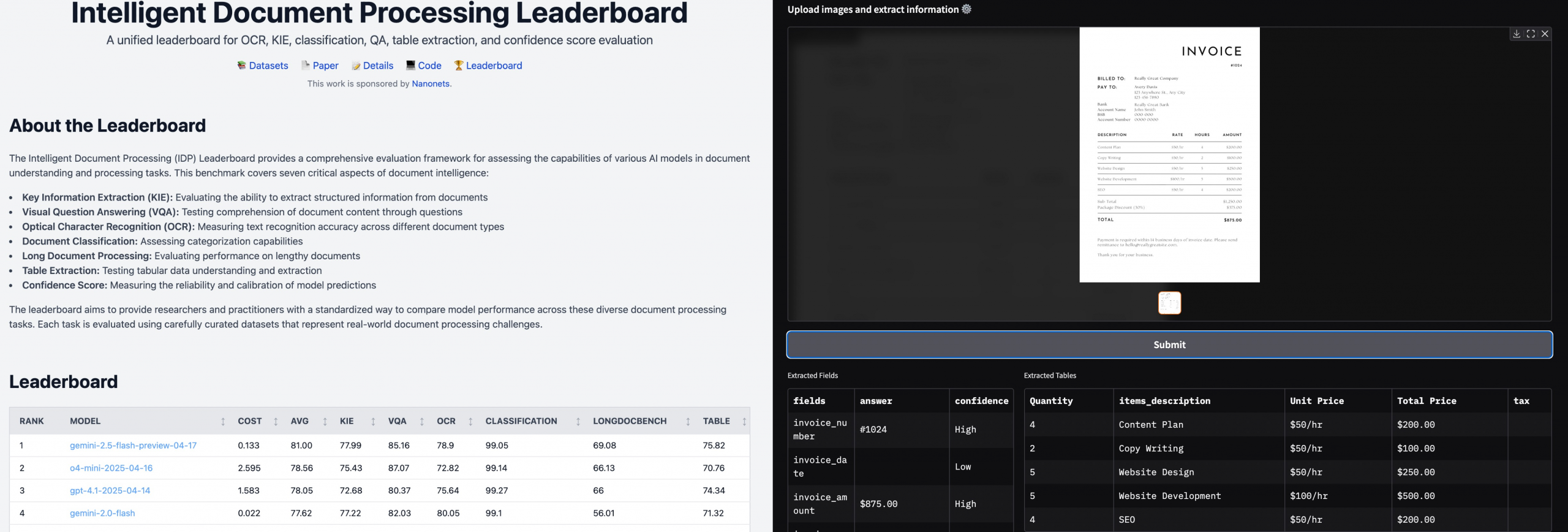
Intelligent Document Processing Leaderboard 跟踪和评估 OCR、关键信息提取 (KIE)、文档分类、表格提取和其他智能文档处理任务中的性能视觉语言模型。
GitHub:https://github.com/NanoNets/docex
特征
智能文档处理排行榜
此基准测试评估了 7 个关键文档智能挑战的性能:
- 关键信息提取 (KIE):从非结构化文档文本中提取结构化字段。
- 视觉问答 (VQA):通过问答评估对文档内容的理解。
- 光学字符识别 (OCR):衡量识别印刷文本和手写文本的准确性。
- 文档分类:评估模型对各种文档类型进行分类的准确性。
- 长文档处理:测试模型对冗长、上下文丰富的文档的推理。
- 表提取:从复杂的表格格式中提取基准结构化数据。
- 置信度分数校准:评估模型预测的可靠性和置信度。
文档
- 灵活提取:定义自定义字段或使用预构建的模板
- 表提取:从文档中提取结构化表格数据
- 置信度评分:获取提取信息的置信度
- 本地部署:完全在您自己的基础设施(Linux、MacOS)上运行
- 多页支持:处理多页文档
- REST API:用于与应用程序集成的编程访问
- 预建模板:适用于常见文档类型的即用型模板:
- 发票
- 护照
- 为其他模板添加/删除新字段/列。
版权声明:本站所有文章版权均归AiNeuOS所有,任何个人、媒体、网站、团体等注明来源后均可以转载。但是不得在非我站的服务器上建立镜像,否则,我站将依法保留追究相关法律责任的权利。
关注公众号:
