微软发布全新的实时文本克隆语音(TTS)模型 VibeVoice-Realtime-0.5B
一、介绍
VibeVoice 是一个新颖的框架,旨在从文本生成富有表现力的长篇多说话对话音频,如播客。它解决了传统文本转语音(TTS)系统中的重大挑战,特别是在可扩展性、说话者一致性和自然轮流方面。尽管模型规模仅为 0.5B,但却具备接近实时的语音生成能力,最快可在约 300 毫秒内开始发声,实现 “话未说完音已先到” 的流畅体验。该模型支持中英文实时转录与语音生成,其中中文表现略逊于英文,但整体依然保持高流畅度与高还原度。
VibeVoice目前包含两种型号变体:
长形式多说话者模型:能够用最多4名不同说话者合成长达90分钟的会话/单人语音,超过许多早期模型中典型的1–2名说话者限制。
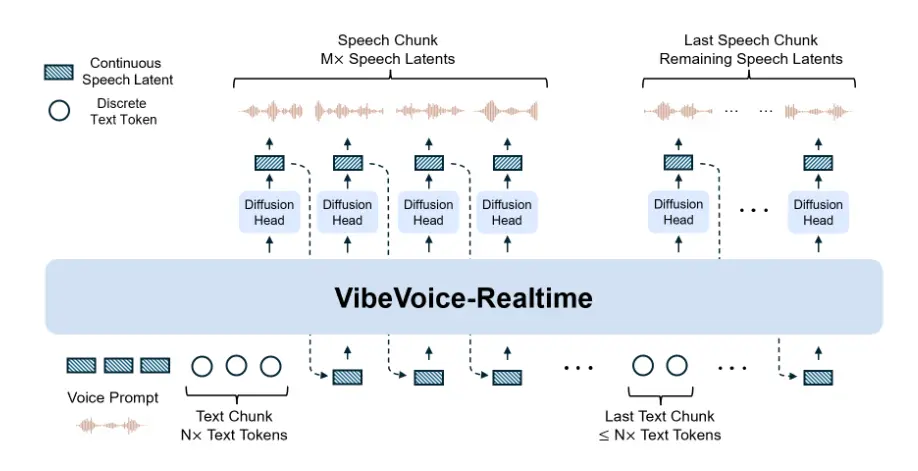
实时流式TTS模型:可在~300毫秒内生成初始可听语音,支持单人实时语音生成的流式文本输入;设计用于低延迟生成。
VibeVoice 的一项核心创新是采用连续语音分词器(声学和语义),以 7.5 Hz 的超低帧率运行。这些分词器高效地保持了音频的真实性,同时显著提升了处理长序列的计算效率。VibeVoice 采用次令牌扩散框架,利用大型语言模型(LLM)理解文本上下文和对话流畅,并采用扩散头生成高保真声学细节。
开源地址:https://github.com/microsoft/VibeVoice。
模型下载:https://huggingface.co/microsoft/VibeVoice-Realtime-0.5B。
二、特性介绍
参数大小:0.5B(部署友好)
实时TTS(~300毫秒,首次可听延迟)
流式文本输入
稳健的长形式语音生成
该实时变体仅支持单扬声器。对于多说话会话语音生成,请使用其他VibeVoice模型(长形式多说话变体)。该模型目前仅针对英语口语;其他语言可能产生不可预测的结果。
为了降低深度伪造风险并确保第一个语音片段的低延迟,语音提示以嵌入式格式提供。对于需要语音自定义的用户,请联系我们的团队。我们还将扩大可用的扬声器产品。
三、快速使用
我们建议使用NVIDIA深度学习容器来管理CUDA环境。
- 启动docker
# NVIDIA PyTorch Container 24.07 / 24.10 / 24.12 verified.
# Later versions are also compatible.
sudo docker run –privileged –net=host –ipc=host –ulimit memlock=-1:-1 –ulimit stack=-1:-1 –gpus all –rm -it nvcr.io/nvidia/pytorch:24.07-py3
## If flash attention is not included in your docker environment, you need to install it manually
## Refer to https://github.com/Dao-AILab/flash-attention for installation instructions
# pip install flash-attn –no-build-isolation
- 从 GitHub 安装
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice/
pip install -e .
版权声明:本站所有文章版权均归AiNeuOS所有,任何个人、媒体、网站、团体等注明来源后均可以转载。但是不得在非我站的服务器上建立镜像,否则,我站将依法保留追究相关法律责任的权利。
关注公众号:
